M_AI 입니다. Loss function의 설명에 이어서, 이제 RetinaNet을 해당 데이터셋에 학습하고, 그 결과를 시각화하여 보여주도록 하겠습니다!
이전글 : [RetinaNet] 4. Loss Function
[RetinaNet] 4. Loss Function
M_AI 입니다. 이전 앵커 박스의 추가적인 설명과 데이터셋 준비에 방법에 이어서, 이제 RetinaNet의 핵심인 Loss function의 설명과 코드를 설명하도록 하겠습니다! 이전글 : [RetinaNet] 3. Prepare the Datase..
yhu0409.tistory.com
이 글을 읽으면 좋을 것 같은 사람들!
- 기본적인 분류(classfication) 모델을 Tensorflow 2.x 버전으로 구현할 줄 아는 사람
- Clssification을 넘어서 Object detection을 하길 원하는데 오픈 소스를 봐도 이해가 가질 않는 사람.
- 오픈 소스를 이해하더라도 입맛대로 수정하는 방법을 모르는 사람.
본 게시글의 목적
※ 본 게시글은 딥러닝 모델의 상세한 이론적 설명보다는 모델 구조를 바탕으로 코드 분석하고 이해하는 데에 목적에 있습니다!
※ 상세한 이론을 원하면 다른 곳에서 찾아보시길 바랍니다!
본 게시글의 특징
① Framework : Tensorflow 2.x
② 학습 환경
- OS : Ubuntu
- GPU : RX570 (AMD)
③ Batch size = 1
④ Kaggle의 RSNA Pneumonia Detection Challenge 데이터셋 사용하여 Chest X-ray에서 폐렴 검출 (Pneumonia detection) 목적.
https://www.kaggle.com/c/rsna-pneumonia-detection-challenge
RSNA Pneumonia Detection Challenge
Can you build an algorithm that automatically detects potential pneumonia cases?
www.kaggle.com
⑤ 게시글에서는 반말
5. Training the Model and Test Result
5.1. Transfer Learning
1~4장에서 앵커 박스부터 RetinaNet의 모델, 데이터셋 준비, loss function을 설명하였다. 이제는 이들을 아울러서 폐렴 데이터셋에 학습할 예정이다.
2장에서 설명했듯이, 본 게시글에서는 ImageNet 데이터셋으로 사전 학습(pre-trained)된 ResNet50을 백본(backbone)으로 하여 학습한다고 하였다. 또한, 본 게시글에서는 백본의 가중치(weights)를 고정(freeze)하고 나머지 계층(layers)에 대한 학습한다. 본 게시글에서 이러한 학습을 진행한 이유는, 백본의 가중치를 고정하지 않고 학습하거나, 백본을 제외한 나머지 계층을 학습 후에 백본 가중치를 학습하면 validation loss가 매우 높게 나와서 이 둘 방법을 제외하였다.
전반적인 코드는 (Figure 24)이며, optimizer는 Keras 예제 코드를 따라 SGD(Stochastic Gradient Descent)로 설정하였다. epoch과 학습률은 여러 실험을 거쳐 설정한 것이다. epoch는 25이며, 5epoch마다 학습률을 낮추어 최소의 validation loss를 찾고자 하였다.

| Parameter | Descrioption |
| Optimizer | SGD |
| Learning rate | [5.0e-4, 5.0e-5, 2.5e-5, 2.5e-6, 1.0e-6] |
| Learning rate scheduler | PiecewiseConstantDecay |
5.2. Result of Training
5.2.1. Prediction Decoding
학습된 모델을 테스트하기 위해 또 다른 코드가 필요하다. 3장 데이터셋을 준비할 때, 각 영상 데이터에 대해 label encoding을 진행하였다. (기억이 나지 않을 시, 3장 필히 참고)
이때, 박스 좌표를 일반 정수형이 아닌, 앵커 박스와의 offset으로 변환하였다. Label encoding 과정 두 박스 간의offset 계산식은 다음과 같다.

RetinaNet은 이러한 값에 학습되었기에, 최종 예측값(prediction value) 또한 이러한 형태로 도출될 것이다. 그렇기에 encoding한 값을 decoding하는 작업이 필요하다. 이를 prediction decoding이라 한다. 단순하게 Label encoding의 역과정이기에 간단하며, 해당 수식은 아래와 같다.

이에 대한 코드는 (Figure 26)이며, 클래스로 구성되어있다.
해당 코드는 본인이 필요에 의해 수정했는데, 수정한 부분은 비-최댓값 억제(Non-Max Suppression, NMS)을 제거하고 예측값 전체를 박스 좌표 부분과 각 박스에 대한 점수(score)를 딕셔너리(dictionary) 형태로 반환하도록 하였다.

5.2.2. Visualization by Heatmap on Image
위에서 필요에 의해 NMS를 제거하였다고 하였다. 이러한 이유는 예측된 박스 중에서 높은 score를 가지는 박스를 찾기보다는, X-ray 영상에서 병변을 직관적으로 찾는 동시에, 색상을 이용하여 시각적으로 병변에 대한 확률을 알아보기 쉽게 하도록 히트맵(heatmap)을 도입하였다.
각 박스마다 가지는 score는 해당 위치에서 객체가 있을 확률을 의미하므로, 각 영역에 대한 확률을 모두 더하여 평균을 내면, 각 위치에 대한 객체가 있을 확률을 전체적으로 알 수 있다. 이를 히트맵으로 시각화한다면 한눈에 쉽게 객체 위치와 해당 위치에 대한 정확도를 알 수 있다. 5.2.1.에서 반환받은 값을 히트맵으로 변환하는 함수는 (Figure 27)이다.

| Parameter | Description |
| divider | 평균을 구하기 위해서 각 영역에 대해 score가 더해진 횟수를 저장하는 변수. |
| label | Ground Truth Box 레이블로, 실제 위치를 박스로 시각화하여 예측한 위치를 비교하기 위해 사용한다. label을 입력 변수로 받지 않을 때는 시각화 하지 않고 무시된다. |
5.2.3. Inference Model
하나의 영상 데이터를 학습된 모델에 테스트하기 위해 설정한 모델로, 이 과정은 일반적인 딥러닝 코드와 크게 다를 것이 없으므로 상세한 설명을 생략한다.
모델을 설정하고, 학습된 가중치(weights)를 가져와(load), 테스트 영상 데이터를 넣어서 나온 예측값을 5.2.1과 5.2.2의 코드를 통해 병변(lesion)을 시각화한다. 해당 코드는 (Figure 28)과 같다.

5.3. Result
테스트 데이터셋에서 일부 영상을 예측한 영상은 (Figure 29)와 같다. 빨간 박스는 실제 폐렴 위치(ground truth)이다.
붉을수록 해당 위치가 병변일 확률이 높다는 것을 의미하고, 푸를수록 낮다는 것을 의미한다.
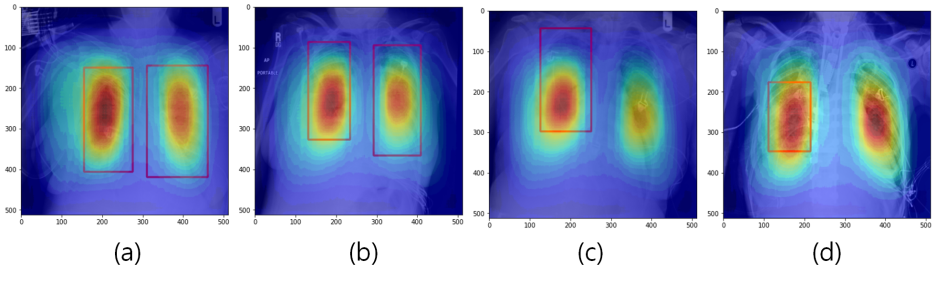
학습된 모델에 대해 테스트한 결과 비교적 병변을 잘 찾는 듯하다. 여기서 (Figure 29 - (a),(b))에서는 잘 찾는 듯 하지만, (c)에서는 실제로 폐렴이 없다고 레이블이 되어있었지만, 테스트 결과로는 어느 정도의 확률이 있다고 나왔다. (d)에서는 (c)보다 더 나쁜 결과가 나왔다.
이러한 결과가 나온 원인을 추측한 결과 원본 데이터의 크기 (1024, 1024)에서 (512, 512)로 축소하면서 발생되는 데이터 손실과 동일한 위치에 있는 데이터로 지속적으로 학습하여 편향이 생긴 것을 추측된다.
이를 해결하기 위해서는 원본 데이터를 그대로 사용하거나, 데이터 증강(data augmentation) 시에 영상 데이터를 회전 및 이동시켜 해당 위치에서 벗어나는 데이터 또한 함께 학습시켜 편향을 완화하도록 한다.
Object detection
- RetinaNet -
끝
Reference
[1] "Focal Loss for Dense Object Detection", "Tsung-Yi Lin and Priya Goyal and Ross Girshick and Kaiming He and Piotr Dollár", 2018, arXiv, cs.CV
[2] "Deep Residual Learning for Image Recognition", "Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun", 2015, arXiv, cs.CV
[3] "Feature Pyramid Networks for Object Detection", "Tsung-Yi Lin and Piotr Dollár and Ross Girshick and Kaiming He and Bharath Hariharan and Serge Belongie", 2017, arXiv, cs.CV
[4] “Object Detection with RetinaNet”, “Srihari Humbarwadi”, 2020.05.17., keras, “https://keras.io/examples/vision/retinanet/”
[5] Resnet50, http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006
[6] “ResNet50 구현해보기”, “eremo2002”, 2019.01.23., https://eremo2002.tistory.com/76
[7] "tf.keras.applications.ResNet50", https://www.tensorflow.org/api_docs/python/tf/keras/applications/ResNet50
[8] "25편 CLAHE", "옥수별", 2015.11.18 , https://blog.naver.com/samsjang/220543360864
[9] "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks", "Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun", 2016, arXiv, cs.CV
[10] "SSD: Single Shot MultiBox Detector", "Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg", 2015, arXiv, cs.CV
[11] "Bounding Box Encoding and Decoding in Object Detection", "Lei Mao", https://leimao.github.io/blog/Bounding-Box-Encoding-Decoding/
[12] "40.1 제너레이터와 yield 알아보기", 코딩 도장, https://dojang.io/mod/page/view.php?id=2412
[13] "tf.data.Dataset", Tensorflow, https://www.tensorflow.org/api_docs/python/tf/data/Dataset
[14] "대용량 훈련 데이터 처리 - Generator로 TF Dataset 만들기", "새옹지인", https://jins-sw.tistory.com/14
'1. 모델 분석 > Object Detection' 카테고리의 다른 글
| [RetinaNet] 4. Loss Function (0) | 2021.05.31 |
|---|---|
| [RetinaNet] 3. Prepare the Dataset (0) | 2021.05.31 |
| [RetinaNet] 2. Explaining overall RetinaNet model and Code analysis (1) | 2021.05.31 |
| [RetinaNet] 1. Anchor Box (2) | 2021.05.31 |