Title
Improving Language Understanding by Generative Pre-Training
Paper Link: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
Abstract
자연어 처리(NLP)는 본문 요약(textual entailment), Q&A (Question answering), 유사성 평가(sementic similarity assessment), 문서 분류 (document classification) 등에 활용되어짐.
비록, 레이블링이 되지 않는 데이터(unlabeld data)는 많지만, 특정 task를 위한 레이블링된 데이터(labeled data)는 현저히 부족한 상황임. 해당 논문의 저자들은 unlabeled text를 활용하여 언어 모델을 Generative Pre-Training (GPT)하여, 특정한 task에 맞게 discrimivative fine-tuning 하여 높은 성능을 보였다고 언급함. 또한, 이전 연구와 달리, 효과적인 전이 학습(transfer)을 하기 위하여 미세 조종(fine-tuning)을 하는 동안, 모델 구조를 최소한으로 변경하는 task-aware input transformation을 활용함. (부가 설명: 특정 task에 따라 입력 구조를 변경하여 fine-tuning하는 방식). 성능 평가과 결과 12개의 성능 평가 방식 중에서 9개 방식에서 state-of-the-art (SOTA) 달성함.
Introduction
NLP에서 raw data를 효과적으로 활용하는 것은 지도 학습에 대한 의존도를 낮추는데 중요함. 왜냐하면 기존 방식은 대부분의 도메인에서 manually labeled data이 부족하기 때문에 NLP를 적용하기에 어려움이 있음. 그래서 unlabeled data를 활용하여 비지도학습 방식으로 모델을 학습하면, 좋은 표현(good representation feature)을 학습하게 되어 상당한 성능 향상이 됨.
그러나, unlabeled data에서 단어 수준(word-level) 이상의 정보를 활용하는 것은 어려움 (부가 설명: 전통적인 NLP 기법에는 개별 단어를 벡터로 변환하는 Word2Vec 방식을 활용하는데, 이는 동음이의어, 다의어, 또는 고유명사와 같은 단어들로 인하여 전체적인 문맥(contextual)을 포괄하기 어렵다는 한계점이 있음. 그래서, 문장 또는 문단 수준과 같은 단어 이상 정보를 고려해야하지만 unlabeled data 활용에는 이 점이 어려움.)
그 이유에는 두 가지 이유가 있음.
1. 불분명한 최적화 방식 (Unclear Optimization Objective): 언어 모델을 학습하기 위한 다음과 같은 다양한 방식이 존재함. 따라서, 어떤 방식을 채택해야 모델이 최적화가 잘 되는 지에 대해 불분명함.
- Lanaguage modeling (언어 모델링): 현재 시점까지 주어진 단어들을 보고 다음 단어를 예측하는 방식
(예: '나는 밥을'이라는 단어들 다음에 나올 수 있는 가장 높은 단어 '먹다.' 를 예측) - Machine Translation (기계 번역): 다른 언어로 변환하면서 의미를 배우는 방식
- Discourse Coherence (담화 일관성): 자연스러운 문장 연결 위주로 학습하는 방식. 즉, 논리적 연결 정보를 학습.
(다음은 Discourse Coherence 이해를 위한 ChatGPT의 부가 설명)
Discourse Coherence (담화 일관성)란?
Discourse Coherence(담화 일관성)는 텍스트가 문장 단위가 아니라 더 큰 문맥에서 얼마나 논리적으로 잘 연결되는지를 의미해. 쉽게 말하면, **문장과 문장이 자연스럽게 이어지는가?**를 판단하는 개념이야.
1. Discourse Coherence의 핵심 개념
- Local Coherence (국소적 일관성)
- 문장과 문장이 바로 옆에서 자연스럽게 연결되는가?
- 예시 (일관성이 있음 ✅):"I went to the store. I bought some milk."
- 앞 문장에서 "store"에 갔다고 했고, 뒷 문장에서 "milk"를 샀다는 내용이 이어지면서 논리적이야.
- 예시 (일관성이 없음 ❌):"I went to the store. The sun is very hot today."
- 첫 문장과 두 번째 문장이 논리적으로 이어지지 않아서 흐름이 끊겨.
- Global Coherence (전역적 일관성)
- 문단, 문서 전체에서 주제가 일관되게 유지되는가?
- 예시 (일관성이 있음 ✅):"I went to the store to buy some groceries. I picked up some milk and eggs. At the checkout counter, I realized I forgot my wallet."
- 모든 문장이 "가게에서 쇼핑하는 이야기"로 이어지고 있음.
- 예시 (일관성이 없음 ❌):"I went to the store to buy some groceries. I picked up some milk and eggs. By the way, did you know that tigers are endangered?"
- 마지막 문장이 갑자기 동물 이야기로 바뀌면서 전체 주제가 흐트러져.
2. Discourse Coherence를 평가하는 방법
기계가 텍스트의 일관성을 판단하려면 몇 가지 기법이 있어.
- Lexical Cohesion (어휘적 결속)
- 같은 단어 또는 유사한 의미의 단어가 반복적으로 등장하면 일관성이 높다고 판단.
- 예시:
"I love apples. Apples are sweet and juicy."
→ "apples"라는 단어가 반복적으로 등장해서 문맥이 이어짐.
- Entity Grid Model (개체 격자 모델)
- 문장에서 언급된 개체(사람, 장소, 사물 등)의 흐름을 추적해서 평가.
- 예시:
pgsql복사편집문장1: John went to the bank. 문장2: He withdrew some money.
- "John" → "He" 로 연결되며 개체 흐름이 유지됨.
- Discourse Connectives (담화 연결어)
- "However", "Therefore", "Meanwhile" 같은 연결어가 자연스럽게 사용되는가를 분석.
- 예시:"It was raining. However, we still went for a walk."
- "However"가 두 문장을 논리적으로 연결함.
3. Discourse Coherence가 중요한 이유
- 텍스트 이해: 사람이 문서를 읽을 때 논리적인 흐름이 깨지면 이해하기 어려워.
- 기계 학습: AI가 문맥을 제대로 파악하려면 문장 간 관계를 고려해야 함.
- 자연스러운 생성 모델: GPT 같은 모델이 문장을 생성할 때, 엉뚱한 문장을 이어 붙이지 않고 자연스러운 흐름을 유지해야 함.
4. Discourse Coherence를 학습하는 방법
GPT 같은 언어 모델이 Discourse Coherence를 배우려면:
- 대량의 텍스트 데이터에서 문맥적 관계를 학습→ 예를 들어, 다음 단어 예측(Language Modeling)을 수행하면 문맥을 고려하게 됨.
- 다중 문장 텍스트에서 담화 연결을 학습→ Transformer 모델은 attention 메커니즘을 이용해서 긴 범위의 문맥을 이해할 수 있음.
- 문장 순서 예측(Task-specific Learning)→ BERT의 NSP(Next Sentence Prediction)처럼 문장 연결이 자연스러운지를 학습할 수도 있음.
2. 불확실한 가장 좋은 fine-tuning 방식 (No consensus on the most effective way to transfer learning): 사전 학습된 모델(pre-trained model)을 fine-tuning을 하기 위해 다음과 같은 방식이 존재하지만, 가장 효과적인 tuning 방식이 확실하지 않음
- 특정 task (task-specific)에 따른 모델 아키텍처 변경
- 복잡한 학습 방법(intricate learning schemes) 활용
- 보조 학습 목표(auxiliary learning objectives) 추가
위의 문제들로 인하여, 저자들은 다음과 같은 방식을 제안함.
반지도 학습 방식 = 비지도 사전 학습 + 지도 미세 조정
Semi-supervised approach = Unsupervised pre-training + Supervised fine-tuning이 방식의 목표는 범용적인 표현 (universal representation)을 학습하여 최소한의 조정 (little adaptation)으로 다양한 task에 활용할 수 있도록 하는 것임. 즉, Foundation model을 만들겠다는 의미. 이를 위해, 대량의 unlabeled data와 소량의 labeled data를 활용함. 이 때, 저자들은 "Our setup does not require these target tasks to be in the same domain as the unlabeled corpus."라고 하는데, 이는 목표 작업 (target task)와 레이블링이 없는 데이터(unlabeled corpus)와 동일한 도메인일 필요가 없다는 의미임. 왜냐하면 비지도 학습으로 사전 학습되는 모델은 범용적인 의미를 잘 파악하고 있으므로, 이 모델을 특정 도메인에 대해 tuning하면 잘 적용되기 때문임.
그래서 모델을 학습하는 개요는 다음과 같음.
1. 딥러닝 모델 가중치 초기화: unlabeled data에 대해 언어 모델링(Language Modeling) 기법으로 비지도 학습
2. 미세 조정: label data로 지도 학습하여 목표 작업(target task)에 맞게 모델 가중치 조정(tuning)
해당 연구에서 저자들이 선정한 모델 아키텍처는 Transformer이며, 순환 구조 신경망 (RNN, LSTM, GRU)에 비해 장기 종속성 또는 장기 기억성(Long-term dependency)을 처리하기 위한 구조화된 메모리를 제공하여 다양한 작업에서 강력한 전이 학습 성능을 제공한다고 함 (This model choice provides us with a more structured memory for handling long-term dependencies in text, compared to alternatives like recurrent networks, resulting in robust transfer performance across diverse tasks).
Inductive bias 측면에서 부가적인 설명을 하자면, 순환 구조 신경망은 데이터의 sequentiality를 분석하고, 트랜스포머는 어텐션 기전을 통해 데이터 요소(elements) 간의 relationship을 통한 globality를 분석함. ViT 논문에 따르면 트랜스포머는 타 모델에 비해 Inductive bias가 약하기 때문에 데이터에 대한 일반화(generalization)을 높이기 위해 많은 양의 데이터가 필요함. 이는 곧, 트랜스포머가 다양한 데이터에 대해서 robust하게 작동한다는 의미임.
또한, 어텐션 기전으로 출력되는 어텐션 맵(attention map)은 데이터 간의 유사도(또는 연관성)를 나타냄(그림 1). 저자들은 이를 구조화된 메모리(structured memory)라고 본문에서 표현함.
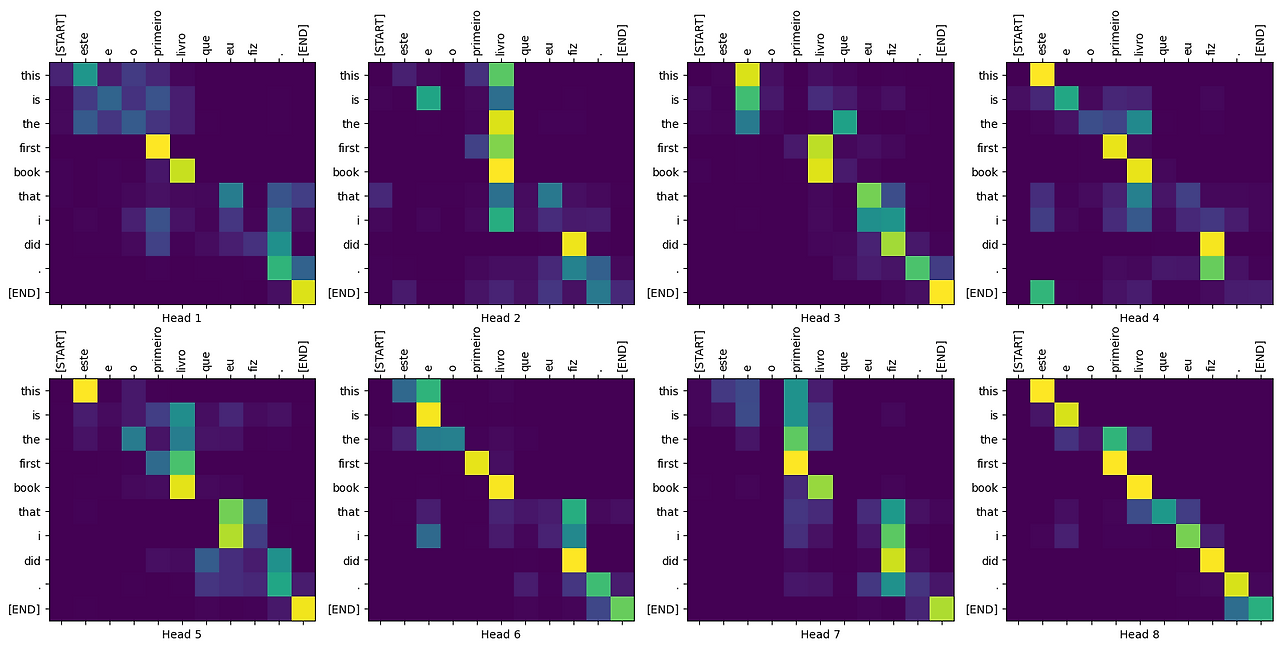
전이 학습 (transfer learning)하는 동안, 저자들은 특정 작업에 맞게 입력을 변형(task-specific input adaptations)하며, 이는 Traversal-Style 방식에서 착안했다고 함. Traversal-Style 방식은 다양한 task의 텍스트를 start token (시작 토큰), delimiter (구분자), end token (마지막 토큰)을 이용하여 하나의 연결된 시퀀스 (sequence)로 만드는 것. 이를 통하여 사전 학습된 모델을 specific task에 맞게 모델에 입력되는 데이터 구조만 변경하여 튜닝하면 모델 구조 변경 없이 가중치만 튜닝되므로 전이 학습에 유용함.
(다음은 Traversal-Style 방식 이해를 위한 ChatGPT의 부가 설명)
Traversal-style 방식이란?
Traversal-style 방식은 구조화된 텍스트 데이터를 개별적인 요소로 나누지 않고, 하나의 연속적인 토큰 시퀀스로 변환하여 처리하는 접근법이야. 즉, 데이터를 구성하는 다양한 요소(예: 제목, 본문, 메타데이터 등)를 개별적으로 다루는 대신, 이를 하나의 긴 입력으로 이어붙여 모델에 전달하는 방식이지.
1. 왜 traversal-style 접근이 필요할까?
기존 NLP 모델들은 일반적으로 다음과 같은 방식으로 입력 데이터를 처리했어:
- 구조화된 데이터를 별도로 다룸 → 예를 들어, 기계 번역에서는 "소스 언어"와 "타겟 언어"를 따로 입력.
- 특정한 아키텍처가 필요함 → 감성 분석 모델, QA 모델, 문서 분류 모델 등 각 작업마다 구조를 다르게 설계해야 했음.
하지만 GPT 같은 범용 모델을 활용하려면, 모델 자체는 동일하게 유지하고 입력 방식만 조정해야 효율적으로 다양한 작업에 적용할 수 있음.
👉 Traversal-style 방식이 이를 가능하게 해줌.
2. Traversal-style 방식의 핵심 원리
Traversal-style 접근은 기본적으로 구조화된 데이터를 하나의 긴 토큰 시퀀스로 변환하는 기법이야. 이를 통해 모델이 다양한 유형의 정보를 한 번에 처리할 수 있게 돼.
📌 기본적인 아이디어:
"텍스트 데이터를 쪼개지 않고, 모델이 자연스럽게 문맥을 이해하도록 하나의 연속된 입력으로 제공한다."
이를 몇 가지 예제로 설명해볼게.
3. Traversal-style 적용 예제
① 문서 분류 (Document Classification)
기존 접근법:
- 제목, 본문, 키워드를 각각 다른 방식으로 모델에 입력해야 함.
- 예를 들어, CNN + RNN을 활용해 본문을 벡터로 만들고, 추가적인 분류기를 붙이는 방식이 필요함.
Traversal-style 접근법:
- 문서의 제목 + 본문 + 키워드를 하나의 토큰 시퀀스로 변환.
- 모델이 이를 하나의 연속된 문맥으로 학습할 수 있도록 입력 형태를 조정.
입력 예시:
➡️ 이렇게 하면 별도의 아키텍처를 변경하지 않고도 문서 분류 작업을 수행할 수 있음.
② 질의응답 (Question Answering, QA)
기존 접근법:
- 질문과 문서를 별도로 입력하고, 특정한 QA 모델을 설계해야 했음.
Traversal-style 접근법:
- 질문과 관련 문서를 하나의 긴 시퀀스로 만들어 입력.
- 모델이 자연스럽게 문맥을 읽고 답변을 도출할 수 있도록 함.
입력 예시:
➡️ 입력 형식만 조정하면 GPT 모델이 자연스럽게 QA 작업을 수행할 수 있음.
③ 기계 번역 (Machine Translation)
기존 접근법:
- 인코더-디코더(Encoder-Decoder) 구조를 활용하여 입력과 출력을 분리해야 했음.
Traversal-style 접근법:
- 번역할 문장과 목표 언어 문장을 하나의 시퀀스로 변환.
- 모델이 이를 자연스럽게 이해하고 변환할 수 있도록 함.
입력 예시:
➡️ 이렇게 하면 GPT 모델이 구조를 변경하지 않고도 번역 작업을 수행할 수 있음.
④ 감성 분석 (Sentiment Analysis)
기존 접근법:
- 감성 분석을 위해 LSTM이나 CNN을 사용하고, 분류기를 따로 추가해야 했음.
Traversal-style 접근법:
- 문장과 감성 레이블을 하나의 시퀀스로 구성.
- 모델이 문맥을 고려하여 감성을 판단할 수 있도록 함.
입력 예시:
➡️ 이렇게 입력하면 GPT 모델이 문맥을 통해 감성을 예측할 수 있음.
4. Traversal-style 방식의 장점
✅ 범용성(Universal Representation) 확보
- 모델 구조를 변경하지 않고 다양한 작업에 적용 가능.
- 미세 조정(Fine-tuning) 없이도 일부 작업 수행 가능.
✅ 효율적인 전이 학습(Transfer Learning)
- GPT처럼 대규모 사전 학습된 모델을 다양한 NLP 작업에 쉽게 적용 가능.
- 특정 작업에 맞춰 입력 방식만 조정하면 됨.
✅ 구조화된 데이터를 자연스럽게 처리 가능
- 테이블, 문서, 대화 데이터 등 다양한 구조의 데이터를 하나의 시퀀스로 변환하여 학습 가능.
✅ 추가적인 모델 설계가 불필요
- 기존의 BERT처럼 특정 태스크(예: QA, 문서 분류)마다 추가적인 구조를 붙일 필요 없이, 입력 형식만 바꾸면 됨.
Related Work
1. Semi-supervised learning for NLP
기존 연구 방식들은 unlabeled data를 사용하여 단어 수준(word-level) 또는 문단 수준(phrase-level)에서 계산하고 지도 학습 방식으로 특징을 활용했지만, 이는 고작 단어 수준에서의 의미 전달만 하는 한계가 있음. 그래서 저자들은 단어 수준 이상의 임베딩 방식으로 고차원적인 의미(higher-level semantics)를 분석하는 것을 목표로 함.
2. Unsupervised pre-training
한 연구에서는 이러한 비지도 사전 학습이 regularization scheme로 작동되어, 더 좋은 일반화 성능을 보인다고 함. 저자들은 비지도 사전 학습으로 딥러닝 모델의 가중치를 초기화하고, 지도 방식으로 가중치를 fine-tuning하는 것을 목표로 함.
3. Auxiliary training objectives
모델을 효과적으로 학습할 수 있도록 보조적인 학습 목표를 추가하는 전략임. 그래서 이전 연구에서는 POS tagging (품사 태깅), sequence labeling 방식으로 보조 목표를 추가하여 성능이 향상된 사례가 있음. 그래서 해당 저자들도 보조 목표를 사용했지만, 보조 목표 없어도 모델이 이미 비지도 학습 단계에서 강력한 언어 능력을 습득했다는 것을 보였다고 함. 즉, 비지도 사전 학습 방식이 보조 학습 목표를 충분히 대체했다고 함.
Framework
앞서 설명했듯이, 본 연구에서 모델은 end-to-end 방식이 아닌 두 단계(two stages) 방식으로 학습됨.
1. Unsupervised pre-training
Loss function: unlabeled data의 토큰들의 집합인 U = {u_1, . . . , u_n} 사용하여, 저자들은 표준 언어 모델링 (standard language modeling) 방법의 loss function을 사용함.
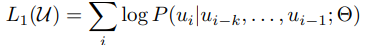
여기서 k는 context windows이며, P는 조건부 확률임. 이 확률은 세타를 가중치로 가지는 모델을 사용하여 계산됨.
해당 수식을 쉽게 설명하자면, 이전 k 개의 단어들을 기반으로 직후에 나올 단어를 예측하는 방법이며 P가 최대가 되도록 모델 학습 유도.
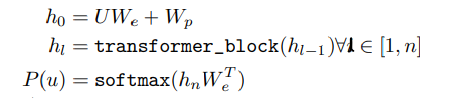
사용하는 모델은 멀티 레이어 트랜스포머 디코더 (Multi-layer transformer decoder)임. U = {u_-k, . . . , u_-1} 는 k개의 단어들의 토큰 시퀀스임. W_e는 전체 토큰들을 임베딩하는 matrix임. W_p는 토큰 순서에 대한 정보를 주는 posional embedding matrix임. n은 트랜스포머의 총 레이어 개수를 의미함.
그래서 각 라인별 수식 설명하면 다음과 같음.
- 해당 모델은 주어진 k개의 토큰 시퀀스(U)를 W_e에서 임베딩 룩업(Embedding Lookup)하여 임베딩하고, W_p에 의해 위치 정보를 추가함.
차원 변환
- UW_e: (k, 1) X (V, d) = (k, d)
- h_0 = UW_e + W_p: (k, d) + (k, d) = (k, d)
- 각 트랜스포머 디코더 블록은 이전 블록에서 출력된 feature (h_l-1)를 멀티헤드 셀프 어텐션(multi-head self-attention)에 의해 계산하여 h_l 출력
차원 변환
- h_l = transforemr_block(h_l-1): (k, d) --> (k, d)
- 마지막 트랜스포머 디코더 블록에서 출력된 feature인 h_n을 트랜스포즈된 W_e와 연산하고 softmax를 통하여 다음에 나올 확률 값을 계산함.
- P(u) = softmax(h_nW_e^T): (k, d) x (d, V) = (k, V) ; 각 단어에 대해 어휘(V) 크기의 확률 분포
2. Supervised fine-tuning
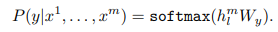
비지도 방식으로 사전학습된 모델을 labeled data인 C로 튜닝함.
위의 수식에서 h_l^m은 마지막 트랜스포머 디코더 블록에서 출력된 feature이고 W_y는 선형 출력 레이어(linear output layer) 가중치임. 이를 연산하고 softmax를 통하여 확률 값을 계산함.
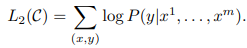
위의 우도를 최대화하는 loss function을 활용함.
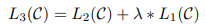
그리고 저자들은 미세 조정을 위하여 언어 모델링을 보조 목표로 포함하면 지도 모델의 일반화 향상 및 수렴 가속도에 도움이 된다는 것을 발견했다고 함. 그래서 앞에서 정의한 두 손실 함수 L1과 L2를 활용한 손실 함수로 모델을 튜닝함.
결과적으로, 미세 조정 과정에 추가적으로 활용하는 파라미터는 선형 출력 레이어 W_y와 구분자 토큰에 활용하는 임베딩임.
3. Task-specific input transformations
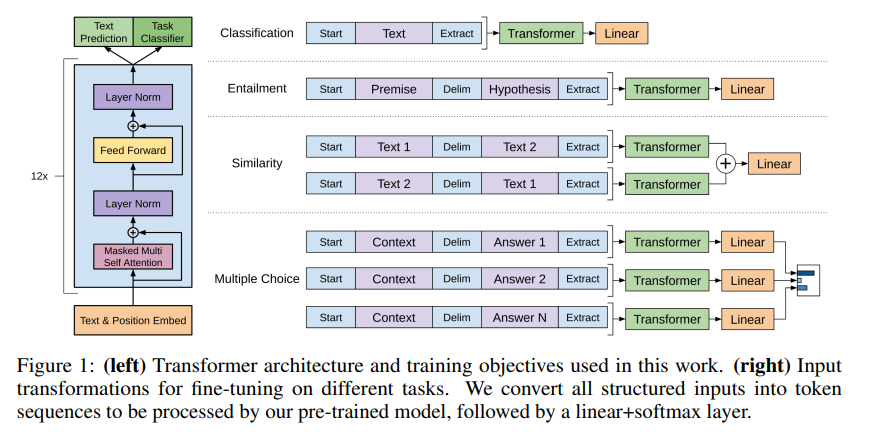
위 그림에서 보이듯이, classification task에서는 별도의 구분자가 필요 없어서, Linear output layer만 있으면 튜닝이 바로 가능함. 그러나 다른 task는 구조화된 Input sequence가 요구됨.
기존 연구들은 모델 구조를 재변경하거나 추가하는 방식으로 했지만, 본 논문에서는 traversal-style approach 방법을 활용하여, 구조화된 입력(structured input)을 정렬된 시퀀스(ordered sequence)로 변환함. 그래서 이 방법을 통하여 모델 구조를 크게 변경하지 않아도 됨.
Classification: 별도의 구분자가 필요없음.
Textual entailment: 전제 (p)와 가설 (h)를 구분자 토큰 ($)을 사이에 두고 연결함.
*Entailment란? 두 개의 문장이 주어졌을 때, 하나의 문장이 다른 문장을 논리적으로 포함 또는 함축하는지를 판별하는 task
Similarity: 두 문장 유사성을 판별하는 task임. 유사성은 문장의 순서와는 관련 없으므로 순서를 바꾸어가며 독립적으로 트랜스포머로 처리함. 이 때, 두 문장 사이에는 구분자가 있어야 함. 그리고 출력된 두 feature를 element-wise로 더하고 선형 출력 계층으로 분석함.
순서 1: [A $ B] --> Transformer --> h_1
순서 2: [B $ A] --> Transformer --> h_2
원소 별 덧셈: h_1 + h_2 = h
선형 출력 레이어: Softmax(Linear(h))
Question Answering and Commonsense Reasoning: context document (z), 질문 (q), 나올 수 있는 답변들 집합 ({a_k})가 주어질 때, 다음과 같이 병합함. [z; q; $; a_k].
즉, 답변들마다 각각 이 형태로 구성함 --> [z; q; $; a_1], [z; q; $; a_2], ..., [z; q; $; a_n]
이를 모델에서 독립적으로 분석하고 softmax를 통해 각 답변에 대한 확률 분포를 생성함.
Experiments
1. Setup
Unsupervised pre-training GPT-1을 사전 학습하기 위해 BooksCorpus라는 데이터셋을 활용함. 연속적인 긴 텍스트(long stretches of contiguous text)를 포함하고 있어, 생성 모델(generative model)이 장기 문맥 정보를 학습하는데 도움이 된다고 저자들이 설명함.
*BooksCorpus database: 다양한 장르(모험, 판타지, 로맨스)를 포함하여 7,000권 이상의 미출판 도서로 구성됨.
유사한 데이터셋으로 ELMo가 있지만, 문장 수준(sentence level)로 셔플되어 있어 장기 문맥 구조가 파괴(destroying)되어 있어 long-term dependency를 학습하기 어려움.
결과적으로, GPT-1은 매우 낮은 수준의 토큰 단위 perplexity (18.4)에 도달함.
* perplexity (PPL) = 모델이 얼마나 헷갈려하는지를 수치화한 값. 즉, 낮을 수록 모델 성능이 높음.
Cross-Entropy Loss 지수 형태로 표현됨.
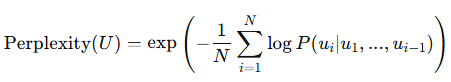
- : 전체 토큰(단어)의 수
- P(u_i ∣ u_1,...,u_i−1): 번째 단어가 앞 문맥을 바탕으로 나올 확률
Model specifications
| 항목 | 세부 내용 |
| Model | Transformer decoder |
| # of Layer | 12 |
| Attention | Masked self-attention |
| Sequence length | 512 tokens |
| Hidden dimension | 768 |
| # of attention head | 12 |
| Postion-wise FFN | 3,072 |
| Optimaize | Adam |
| Learning rate | 0~2,000 : From 0 to 2.5e-4 using Warm-up linearly 2,000~: From 2.5e-4 to 0 using Consine schedule |
| Epoch | 100 |
| Batch size | 64 |
| Initailization | LayerNorm으로 단순히 N(0, 0.02)로 초기화 |
| Tokenizer | Bytepair encoding (BPE) 사용, 40,000개의 병합된 토큰 |
| Dropout | Residual, Embedding, Attention에 각각 dropout 0.1 적용 |
| Regularization | 수정된 L2 정규화 사용, w=0.01 (bias와 gain에는 제외) |
| Activation function | GELU |
| Positional embedding | learnable position embedding (not consine) |
| Data preprocessing | 텍스트 정리: ftfy (이상한 문자 인코딩, 깨진 글자 등을 처리0 토크나이징: spaCy |
* Warm-up: 학습 초반에 작은 학습률로 시작하여 천천히 증가시키는 방법 (안정적으로 시작)
Fine-tuning details GPT-1을 다양한 task에 맞게 downstream 하는 방법.
| 항목 | 세부 내용 |
| 하이퍼파라미터 | 사전학습과 동일 |
| Classifier dropout | 0.1 |
| Learning rate | 6.25e-5 using Warm-up (전체학습 구간 0.2%까지)+ Linear Decay |
| Batch size | 32 |
| Epoch | 3 |
| L2 정규화 계수 λ | 0.5 |
2. Supervised fine-tuning
일부 task에서는 GLUE 벤치마크로 활용
Natural Language Inference (NLI)
문장 2개(Premise, Hypothesis) 간의 관계를 판별하는 task. 나올 수 있는 관계(label)은 Entailment (함축), Contradiction (모순), Neutral (중립) 임.
NLI가 어려움 이유는 다음과 같은 언어적 현상 때문임.
- Lexical entailment: 단어의 의미의 포함 관계
- Coreference: "He", "She", "it" 등이 누구를 지칭하는지 파악
- Lexical/Syntactic ambiguity: 단어 또는 문법 구조의 다의성 (예, 동음다의어)
저자들은 GPT-1 평가에 5가지 데이터셋을 활용
| 데이터셋 | 설명 |
| SNLI | 이미지 캡션 기반 NLI 데이터셋 |
| MNLI | 다양한 장르 (소설, 스피치, 정보 보고서 등) 포함 |
| QNLI | 위키피디아 문서 기반 질의응답 형식 |
| SciTail | 과학 시험 문장들 기반 |
| RTE | 뉴스 등 기반의 작은 규모 데이터 |
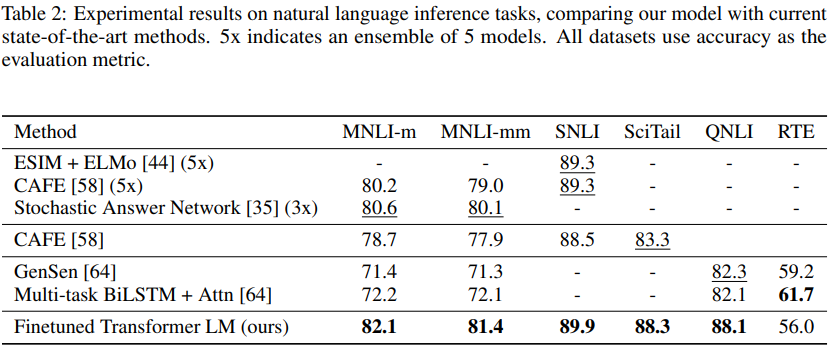
RTE 데이터셋을 제외한 다른 데이터셋에서 GPT-1이 기존 모델 대비 높은 성능을 보임. 저자들은 RTE는 데이터 규모가 작아서 성능이 낮았을 것으로 추측함. 그리고 Multi-task learning을 하면 성능이 더 좋아질 것으로 예상하지만 아직까지는 테스트하지 않았다고 덧붙임.
Question answering and commonsense reasoning
단일 문장 또는 여러 문장을 추론하는 작업.
| 데이터셋 | 세부 설명 |
| RACE | 중고등학교 영어 시험 지문과 문제로 구성 추론/이해/요약 능력 요구 |
| Story Cloze Test | 짧은 이야기의 마지막 문장을 2개 중에서 골라야 함 (Commone Sense Reasoning) |
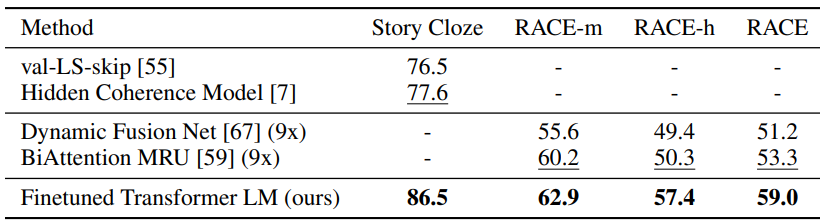
두 데이터셋에서 모두 높은 성능을 보임.
Semantic Similarity
두 문장의 유사성을 판단하는 task.
| 데이터셋 | 설명 |
| MRPC | 뉴스 기사에서 문장 쌍 추출, Paraphrase 여부 |
| QQP | Quora 사이트에서 질문 쌍, 의미가 같은지 판단 |
| STS-B | 두 문장의 의미 유사도를 점수(0~5)로 평가하는 회귀 문제 |
Classification
문장 하나를 보고 클래스를 예측하는 task
| 데이터셋 | 설명 |
| CoLA | 문장이 문법적으로 맞는지 여부 판단. Linguistic bias 평가 |
| SST-2 | 감성 분석. Binary classification 수행 |
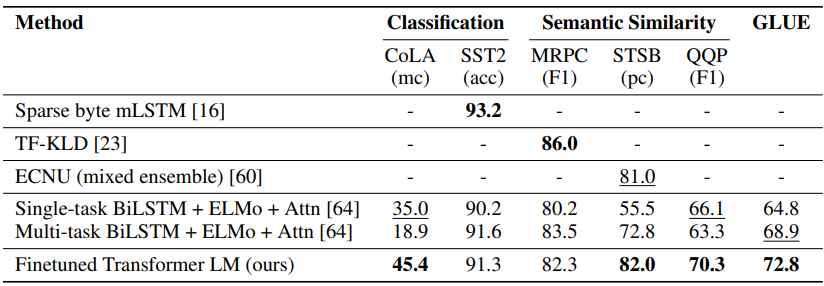
Analysis
Impact of number of layers transferred
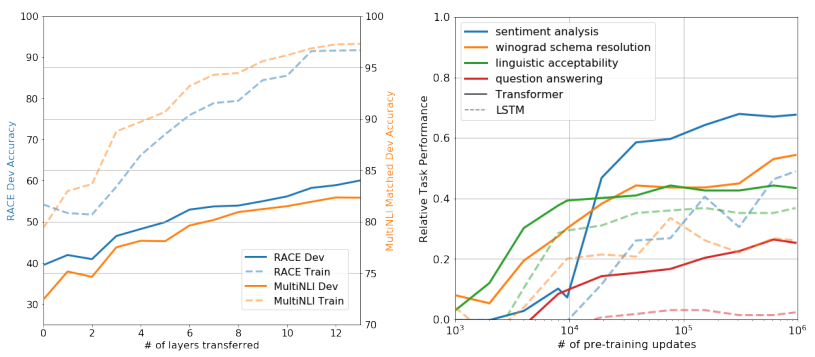
위 figure의 왼쪽 그래프에서, 저자들은 embedding layer만 전이하는 것보다, Transformer 레이어를 더 많이 가져올수록 성능이 향상된다고 언급함. 이는 곧, transformer의 각 층이 의미 있는 언어 기능을 학습하고 있다고 의미함.
Zero-shot Behaviors
fine-tuning 없이도, 단순 사전학습된 GPT-1 모델이 특정 작업을 어느 정도 수행할 수 있는 지에 대해 실험.
실험 방법
- fine-tuning을 전혀 하지 않고, 단순히 GPT-1의 생성 확률(log-probability)을 이용해서 답을 유추
- 특정 작업에 맞는 heuristic 룰을 만들어서 답을 고름
| 데이터셋 | Zero-shot 방식 |
| CoLA | 문장의 평균 token log-prob 사용, 정해진 threshold로 판단 |
| SST-2 | 문장에 “very” 추가 후, "positive"/"negative" 중 log-prob 높은 쪽 선택 |
| RACE | 각 보기에 대해 GPT가 예측한 log-prob 평균값 비교 후 선택 |
| DPRD | 대명사를 각 후보로 치환 후, 이후 문장의 log-prob를 비교 |
실험 결과, 사전 학습이 진행될수록 zero-shot 성능도 향상 (위의 figure에서 우측 그래프)되며, Transformer는 구조 자체가 Inductive bias가 전이에 유리하여 LSTM보다 일관적이고 안정된 성능을 보임. (LSTM은 성능 변동성이 큼)
Ablation studies
모델의 일부 구성요소를 제거했을 때, 성능이 어떻게 변하는지 실험
| 방법 | 설명 | 결과 | 특 |
| Transformer + Auxiliary LM | 74.7 | ||
| Transformer w/o pre-training | 사전학습 없이 바로 supervised 학습만 | 59.9 (-14.8점) | pre-training의 중요성 |
| Transformer w/o auxiliary LM | fine-tuning 시 auxiliary objective 제거 | 75.0 | |
| LSTM + Auxiliary LM | Transformer 대신 LSTM 사용 | 69.1 (-5.6점) | 모든 태스크에서 성능 낮음 (특히 긴 문맥에 약함) |
*Transformer w/o auxiliary LM 실험은 본 논문에서 설계한 손실함수(아래 수식)에서 L1(Auxiliary objective)를 제외한다는 의미임.